利用云计算、大数据技术,构建涵盖关系型数据库、分布式文件系统、NOSQL数据库、内存数据库等混合型数据资源中心,建立高安全、高可用、高扩展的智慧环保大数据中心数据架构,更好地解决未来5-10年大流量、高并发、高响应、高实时需求所带来的计算、存储、扩容、负载均衡等问题。
同时按照标准先行的思路,整合环保各类数据资源,建立可知、可管、可控、可用的数据资源管理与服务平台,依托平台,向各类专业应用、综合应用、移动应用等提供统一的数据资源管理、分析及服务。
(一) 数据资源标准制定
数据资源标准制定通过研究数据资源处理与管理的理论和方法,结合菏泽市环保数据资源的特点,梳理当前环保数据资源存在的问题,并参照环保监测的政策法规,以“标准化、模块化、统一化”的原则进行设计,完成对菏泽市环保数据资源标准制定,采用多层体系结构设计,将用户界面、用户逻辑、数据相互分离,最终建立包含数据管理、数据处理、数据展示的数据共享及应用的平台。
(二) 环境信息资源服务平台
1 建设目标
环保大数据中心数据层的建设,按照以数据资源为核心的理念,充分利用基础设施与各类大数据服务,实现各类环保数据资源、企业数据资源以及互联网数据资源的整合汇集、存储组织、分析处理以及标准化管理,通过环保大数据中心数据层,将各类资源数据以服务接口等形式提供给上层各类应用。
环保大数据中心数据层的建设目标主要包括以下几方面:
1、搭建标准化数据资源中心
基于目前各业务系统积累的各类数据资源结构特点与实战应用特点,利用关系型数据库、海量数据库、分布式文件系统、内存数据库等多种存储技术,搭建数据资源整合平台,实现环保结构化数据、半结构化数据以及非结构化数据的整合汇集、标准转换、存储组织。
2、实现环保信息资源全息化管理
对环保内部各个应用系统、数据库、数据表以及数据项等各类信息资源进行管理,实现对环保内部资源布局等情况的精准掌控。同时依据相关国家标准、部颁标准,对各类资源进行标准化处理,形成标准化的信息资源,提升各级单位及部门的标准化信息资源服务与支撑能力。
3、构建高效灵活的数据分析处理平台
利用大数据分布式计算、内存计算以及流式计算等关键技术,建立高效能、松耦合、可扩展的环保大数据中心分析处理平台,围绕数据挖掘分析、信息综合应用,在海量数据、高并发等条件下,为各业务部门需求提供数据检索、数据关联、数据分析、数据挖掘等数据处理服务支撑。
4、建设一体化数据服务体系
以满足各环保部门应用需求为目的,基于环保大数据中心数据中心构建数据服务接口,为各个应用系统提供数据服务。同时对环保内部数据服务进行集中式管理,以环保大数据中心为中心对外提供一体化、标准化数据服务,进而实现环保各类数据服务由原来的点到点模式转变为由点到面的模式,提高数据资源服务能力和管理水平。
5、建立数据与服务安全可靠保障机制
利用数据加密等安全技术对关键信息资源进行加密存储传输。同时,强化数据使用权限控制和数据使用审计,保证数据资源在存储过程、传输过程、使用过程等各个阶段的安全。
2 总体架构
数据层是整个环保大数据中心核心组成部分,在规划建设过程中,坚持以数据资源为核心,面向数据资源应用与服务、环保信息数据资源标准化与管理,实现数据资源横向集成、纵向贯通、全局共享的运转模式。信息资源服务平台逻辑架构如下图:
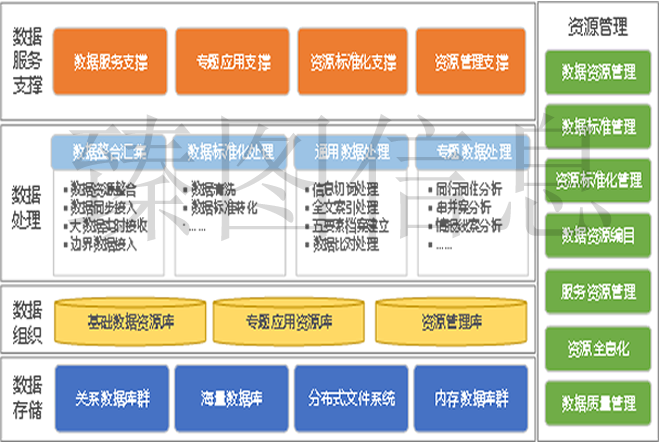
整个信息资源服务平台逻辑组成部分有数据存储、数据组织、数据处理、资源管理、数据服务支撑。
数据存储:主要采用关系数据库群、海量数据库、分布式文件系统以及内存数据库等多种数据存储技术,以满足环保结构化、非结构化多种类型格式的海量数据资源存储需求。
数据组织:对各类数据资源进行逻辑组织,形成基础数据资源库、专题应用资源库以及资源管理库,满足环保数据资源应用、管理与服务的需求。
数据处理:主要包括数据整合汇集、数据标准化处理、通用数据处理、专题数据处理。从多个层面对数据资源进行分析挖掘,为不同业务需求提供数据处理服务支撑。
资源管理:资源管理从应用资源、数据资源、服务资源以及标准资源多个层面实现环保大数据中心内外信息资源的管理与标准建设。
数据服务支撑:环保大数据中心数据从数据服务、专题应用、标准化以及资源管理提供环保信息化服务支撑能力。
3 数据集成
数据集成系统是将各个源头数据资源迁移至环保大数据中心数据资源中心中,实现多种类型环保数据资源集成处理。
数据集成系统利用不同技术对数据进行集成,借助增量数据监测、数据日志分析、大数据集成等技术,采集整合各类环保大数据中心平台外的数据资源并装载到数据资源中心中的原始数据资源库中,并保持数据资源的实时鲜活。
根据数据来源的分析,有关污染源的数据集成方案如下:
|
数据来源 |
数据集成方式 |
频率 |
说明 |
|
环境统计 |
手动执行导入包 |
每年 |
1、整合历史数据包括“十一五”环统、“十二五”环统数据一次性导入中心数据库; 2、新增数据通过数据导入包每年导入中心数据库。 |
|
污染源普查 |
手动执行导入包 |
每十年 |
1、整合历史数据包括2007及2009污染源普查数据、2010年污染源普查动态更新数据 |
|
排污申报 |
手动执行导入包 |
每年 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据导入包每年导入。 |
|
排污收费 |
定期直接入库 |
每月 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据导入包每月导入。 |
|
污染源监督性监测 |
数据接口自动入库 |
实时 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据接口实时进入中心数据库 |
|
污染源在线监测 |
数据接口自动入库 |
实时 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据接口实时进入中心数据库 |
|
建设项目 |
数据接口自动入库 |
实时 |
1、整合历史数据一次性导入中心数据库; 2、新增数据通过数据接口实时进入中心数据库。 |
|
排污许可 |
数据接口自动入库 |
实时 |
1、新增数据通过数据接口实时进入中心数据库。 |
|
其他行政许可 |
手动执行导入包 |
每月 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据导入包每月导入。 |
|
环境监察 |
数据接口自动入库 |
实时 |
1、新增数据通过数据接口实时进入中心数据库。 |
|
行政处罚 |
手动执行导入包 |
每月 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据导入包每月导入。 |
|
移动执法 |
数据接口自动入库 |
实时 |
1、新增数据通过数据接口实时进入中心数据库。 |
|
信访投诉 |
手动执行导入包 |
每月 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据导入包每月导入。 |
|
企业基础信息 |
数据接口自动入库 |
实时 |
1、历史数据通过填报后对接导入; 2、新增数据通过数据导入包每月导入。 |
|
危险废物管理 |
数据接口自动入库 |
实时 |
1、整合历史数据一次性导入中心数据库; 2、新增数据通过数据接口实时进入中心数据库。 |
|
辐射安全管理 |
数据接口自动入库 |
实时 |
1、整合历史数据一次性导入中心数据库; 2、新增数据通过数据接口实时进入中心数据库。 |
|
生态管理 |
手动执行导入包 |
每月 |
1、整合历史数据一次性导入数据库; 2、新增数据通过数据导入包每月导入。 |
环境质量数据集成方案
环境质量相关的数据从来源来说相对单纯,因此其数据集成主要有如下方式:
|
数据来源 |
数据集成方式 |
频率 |
说明 |
|
手工监测数据 |
数据接口自动入库 |
定期 |
1、定期通过数据接口实时进入中心数据库。 |
|
环境质量在线监测 |
数据接口自动入库 |
实时 |
1、新增数据通过数据接口实时进入中心数据库。 |
|
环境监测历史数据 |
手动执行导入包+集成管理 |
一次性导入 |
1、整合历史数据一次性导入中心数据库。 |
3.4.4纸质档案电子化入库
菏泽环保局还存在大量的历史环保数据,这些数据是以纸质文件的方式存档的,在环境资源数据中心的建设中,必须考虑对这部分数据进行电子化入库。
4 数据质量
数据质量管理基于环保大数据中心数据资源中心采集的各类数据资源,进行数据质量检测、数据质量问题发现、跟踪以及修正,确保环保大数据中心对各个业务部门提供可用、高质量的数据资源。
环保数据资源中心建设中不仅要提高数据的准确性,而且要保障资源中心中数据资源的完整性、唯一性、合法性、一致性、及时性等;通过明确数据质量的组织、流程、方法的管理框架,建立数据质量监控机制,及时发现、报告、处理仓库系统中的数据质量问题。从技术和用户角度考虑和衡量数据质量问题,提高用户对数据的满意度。
加强数据质量评估,根据评估指标和评估方法,实现对系统源接口基础数据质量的评价和基础编码评估,发现数据质量潜在的问题和规律,作为系统数据质量改进的参考和依据。
建立数据质量报告功能,实现对数据质量子系统各种信息的汇总、梳理、统计和分析,提供全面及时的数据质量报告,预防和控制错误范围的扩大,便于数据质量管控信息总结、知识沉淀和经验重用。
5 数据标准化
数据标准化是环保大数据中心数据层建设的基础。在项目建设时根据环保信息资源标准,并根据实际情况进行完善。环保大数据中心数据标准化工作主要以下几个层面出发进行建设:
数据内容标准化
通过依据现有相关标准内容,对整合的各类数据资源进行标准化处理,形成标准化数据资源,从而对各个业务部门提供标准化的数据资源服务。
资源管理标准化
通过对信息资源注册、梳理、对标等一系列的工作,建立标准化的资源管理机制,实现对全部信息化资源的标准化管理。以管理推动信息标准化应用工作,逐步实现环保信息化建设的规范化、标准化。
标准化建设
数据标准化工作是一项长期的过程,随着信息化的升级和深入,数据标准体系也在逐渐完善,所以通过制定相应的信息管理规范,必要时制定相关信息管理制度,来规范和长期完善环保大数据中心标准管理平台,保证数据资源标准化工作开展和标准化工作成果的形成。
6 数据资源中心
数据资源中心采用传统关系数据库技术与大数据、分布式存储等先进云计算技术相结合方式搭建形成,用于存储组织各类环保内部数据资源、企业数据资源以及互联网数据资源等。
数据资源中心一方面要满足汇集多种类型数据资源存储需求,另一方面要满足对外提供高效标准的数据服务支撑需求,同时面向具体业务需求要满足高效灵活的数据分析处理需求。因此在存储组织时依据各种数据资源的物理特性、业务应用需求特性等,对各类数据资源进行科学合理规划组织,用以存储环保内部、企业以及互联网来源数据资源中的结构化、非结构数据资源。
7 基础数据资源库
基础数据资源库用以存储通过整合汇集环保内部、被监控企业单位、互联网取得的各类共享原始数据资源,以及对这些数据资源进行标准化、规范化转换加工后的标准数据资源。基础资源库主要包括原始数据资源库与标准数据资源库。
基础数据资源库根据数据资源特性以及数据资源应用场景选择采用传统结构化关系数据库、海量数据库、分布式文件系统等多种存储方式,综合利用各项存储技术强项,以提高数据存储与处理效率。存储原则:对于数据量小、结构关系复杂或需要进行事务处理的数据资源主要采用关系数据库存储;对于数量大、结构相对简单的数据资源采用海量数据库存储;对于非结构化数据资源主要采用分布式文件系统进行存储;对于数据实时性要求或处理要求较高的采用内存数据库存储。
为确保数据资源中心数据资源安全以及稳定高效运行,原则上基础数据资源库不直接对外提供应用级的数据库挂接、数据资源下载以及抽取等操作。各类数据资源需求按照通过数据服务接口方式获取,或通过云数据总线挂接数据处理工具构建形成专题应用数据资源对外提供数据服务。
基础资源库主要包括原始数据资源库与标准数据资源库:
1、原始数据资源库
利用数据集成系统实现各个源头数据资源的完整原样复制,将数据资源从源头汇集到环保大数据中心数据资源中心中。
在数据整合汇集过程中不对源头数据资源的数据结构、数据内容做任何改动,主要目的一是减少数据汇集过程的复杂程度,确保数据整合汇聚效率并提高数据实效性,避免传统模式下同步进行数据转换处理时发生错误导致的数据重新汇集。二是满足某些环保业务对原始数据资源的需求,同时可基于原始数据资源实现多次多层面对数据深度应用支撑。三是原始数据资源库可作为原始凭证,在数据出现不一致或错误情况下可对数据情况进行回溯调查。四是通过原始数据资源做进一步的数据质量检查工作,以促使源头数据资源质量提高。
2、标准数据资源库
基于环保部颁标准、国家相关标准、其他部委相关标准,同时结合自定义标准,利用标准数据转化工具将集中在原始数据资源库中的数据资源经过清洗转化等一系列操作后,形成标准化环保数据资源进行存储。
标准数据资源库是数据资源中心对外提供数据资源服务的主要部分。主要作用一是对外提供标准化数据服务,二是基于标准化数据资源为各个业务部门需求提供数据关联、分析挖掘等处理。
7.1 专题应用资源库
为满足环保各类业务需求,建立多种专题应用业务模型,通过对数据资源的挖掘分析、关联串并、索引化等数据处理方式构建形成专题应用资源库。
专题应用资源库中主要存储按照不同业务主题、不同需求纬度、不同粒度的组织形成的综合关联数据、专题业务数据、全文索引数据等。为实现纵向和横向跨业务部门数据资源深度利用、创新环保应用提供专题数据服务。
根据专题数据应用方式,以及共享程度、存储粒度和应用层次,应用服务资源库分为关联数据库、专题数据库、全文索引库等。
1、关联资源库
以三要素为核心,对各类数据资源利用关键信息进行关联串并和再组织,建立形成“企业、案件、环境”关联资源库,为信息资源综合查询提供数据基础支撑。例如构建形成的企业档案、办案案件档案、环境档案(例如环保监控河流、水库等)等信息。
2、专题资源库
按照业务应用具体需求,对各类数据资源进一步分析挖掘。按照业务需求建立数据聚合、信息比对、统计分析等各种业务处理模型,并对分析结果数据资源进行固化后,形成适合各类业务应用的专题数据库,如造假可疑企业信息库、溯源信息库、决策分析信息库等。
3、全文索引库
全文索引库主要包括标签数据和索引数据。对于各类结构化数据、网页数据、文档数据等资源,通过切词处理、语义标注分析等操作后,通过提取关键字和关键信息建立形成标签数据。通过对数据资源建立索引关系形成索引数据,实现对特定信息快速检索与定位。
7.2 资源管理库
为了对环保信息资源进行科学有效的管理,实现对信息资源的可知、可管、可控,构建资源管理库。
信息资源库
信息资源库主要对环保内部各个基础信息资源进行管理,范围包括应用系统的数据库、数据表以及数据项等内容,并且按照信息资源行业分类、业务分类、所属单位部门等内容进行管理。
数据元标注库
利用标准环保数据元对数据项进行标准化标注,建立形成应用系统——数据库——数据表——数据项——同义词——数据元关联。
共享数据资源目录库
基于根据环保数据资源目录注册接口规范与环保部信息资源目录要求,对数据资源名称、摘要、分类、共享属性、公开属性、数据资源提供方等内容进行明确,对已注册的基础资源按照业务、层级等进行编目,形成共享数据资源目录。
标准资源库
标准资源库主要实现各类标准资源数据的管理。标准资源库将与环保部相关标准系统进行对接,实现标准资源的同步。标准资源库建设依据国家相关标准、环保部部颁标准、其他行业相关标准内容,主要包括以下组成部分:
数据元及同义词数据
主要管理标准数据元以及同义词。数据元是用于定义业务相关数据结构的基础元素,主要以环保部颁布形成的《环境信息元数据规范》为基础建设形成。
环保数据元也包括省、地市局根据本地实际情况整合、梳理、审定、上报形成的本地数据元信息。
同义词是在标准数据元基础之上进行构建形成,主要实现各类注册数据资源与数据项进行标准化对照提供支撑。
代码字典数据
标准代码字典数据是环保大数据中心数据标准的核心要素之一,其内容建设主要纳入国家相关标准、环保部部颁标准、其他行业相关标准等标准文件规定的代码字典信息项。
标准主数据
主数据是对各个系统之间共享数据进行标准化管理。例如用户信息、组织机构信息、地址信息、单位信息等数据。由于原有各条线在各个系统中这些数据资源参照的标准不一或无标准参照,导致目前在数据综合利用过程中,各个数据资源难以融合,消耗了大量时间和人力进行梳理。
因此通过对这些主数据资源进行统一管理,遵循有标准的依据相关标准建设,无标准依据的制订本地化标准的建设原则,建立标准化的主数据资源,逐步实现各个业务应用系统之间主数据标准化映射。
8 数据分析处理
数据分析处理主要面向各个业务对数据分析利用的需求,构建一套基于数据资源中心的数据分析处理流程,使数据分析处理变得高效灵活。
8.1 数据总线
数据总线
数据总线负责对各类数据资源进行传输,通过数据推送引擎将需要处理的数据资源推送到数据总线中,并有挂接到数据总线中的数据处理引擎负责从数据总线中获取相应的数据资源,并对这些数据进行加工、分析处理。
数据推送引擎
数据推送引擎通过云数据总线任务调度,实现将数据资源推送至数据总线中。主要包括任务调度与解析、数据资源获取、数据资源推送、推送日志记录等功能。
数据总线管理
主要针对数据总线进行配置管理与监控功能。
数据处理工具配置管理:主要实现各个数据处理工具的挂接与管理,包括数据处理工具列表、数据处理工具注册、数据处理工具上下线管理、数据处理工具状态等。
数据推送引擎配置管理:包括数据推送任务定制、任务调度与解析、数据推送引擎状态等内容。
数据总线状态监控:包括数据推送引擎状况、推送数据资源量、数据处理工具运行状况。
8.2 数据处理引擎
数据处理引擎采用分布式计算、实时计算等多种数据处理技术,为满足环保业务需求构建全文索引化、信息关联化以及数据挖掘分析的多种数据处理模型。
标准数据转化工具
依靠标准化数据资源,对数据整合系统采集的各类原始数据资源进行清洗、标准化转换等数据预处理,最终形成环保大数据中心标准数据资源。
索引处理工具
海量信息索引处理引擎从基础数据资源库、专题应用资源库等数据资源中抓取全部或关键信息对数据资源进行标记,形成索引信息,为实现各类数据资源快速高效检索建立形成全文索引库。
档案处理工具
档案处理工具根据三要素,通过对基础数据资源库中的标准资源进行深度信息关联串并,形成“一厂一档”等综合档案信息,构建形成关联信息库。
比对数据处理工具
对各类环境业务数据信息,按照分布式压缩文件格式进行分区存储,并加载到大数据比对引擎中,为海量数据的实时快速比对碰撞提供高效的比对数据支撑。
专题数据处理工具
根据环保不同部门工作需求,以数据中心聚合和组织的数据为基础,开展面向主体业务的和面向决策的数据分析工作,提供快速、灵活的大数据量复杂查询与分析处理,面向业务实际需求和管理决策提供专题数据服务。
9 数据服务
数据服务主要是将数据资源中的标准数据资源与专题数据资源按照业务需求建立形成数据服务接口,为各业务部门提供标准化、共享的、安全的数据服务,实现数据资源对外统一服务、资源共享与管理。
主要目的一是提高数据资源安全性,有效防止外部应用对底层数据资源的直接访问;二是提高数据服务稳定性,确保数据资源中心的高效稳定运行;三是对数据服务进行授权管理以及应用管理,保障数据服务安全可控;四是对数据资源利用情况进行有效管理监控。
(三) GIS服务扩充
利用现有三维GIS平台,制作生态环境专题图,发布各类专题地图服务,为上层应用提供地图服务、分析服务。
(四) 数据资源创新应用
1 环保云搜
环保云搜是基于大数据应用支撑平台基础上的环保云应用,通过类百度的方式实现环保业务相关信息的快速搜索。
环保云搜的设计立足于业务实战,并充分借鉴了互联网搜索的易用性、智能性。系统基于分布式全文检索引擎,让用户使用多维度的碎片信息即可在海量数据中进行地毯式搜索,如在搜索框中输入:“杭州 COD *水务公司”等多维度碎片信息,即可搜索出符合检索条件的企业信息,实现由企业关联污染源、站点、案件、水务公司等信息,通过一个输入框即可实现任意要素间关联搜索。
2 超级档案
根据环境监管监察的业务体系和环境对象,建立污染源企业、监测站点、河流(湖库)、工业园区四类重点监管对象的超级档案,构建重点监管对象的全景视图,包括基本信息、监测信息、监察信息、视频信息、画像信息、统计信息、分析信息等,为用户提供全方位、多维度、自分析的对象“超级档案”。
3 企业画像
所谓大数据企业画像,就是用大数据技术,对环保系统、企业、第三方等的数据进行分析和应用,汇集企业基本信息、生产要素、管理要素、环境要素等多个成像要素,涵盖环境影响评价、建设项目审批、竣工验收、行政许可、现场检查、环境监测、行政处罚、排污收费、信访投诉、环境信用评价等业务,利用大数据标签刻化技术对企业‘打标签’。
以企业主体为例,通过企业画像构建,改变监管部门只能凭借其业务经验进行主体对像分析,尤其在环境信息化数据量越来越多的今天,监管部门可以通过特征标签(COD、氨氮、设备陈旧、落后产能、环保电价、位置跨境、有超标处罚、高架源、有作假前科、永久关停、水气共有等)快速定位目标企业,快速挖掘出监管人员所需要的业务信息,对监管分析提供有价值的参考,缩短人工分析时间,为监管人员制定精准化决策提供支撑。
4 环保智库
依托云计算大数据平台,建设一站式环境知识库服务平台,旨在解决工作人员在学习、工作当中对环境信息的需求,方便其快速、便捷地获取到实用的环境信息,辅助决策参考。
包括污染源知识库(废水、废气、噪声、固废、核与辐射、工地扬尘、机动车尾气)、环境质量(水环境、大气环境、声环境、生态环境)、环境业务知识库(建设项目管理、监督许可管理、污染源日常监督、行政处罚管理、环境监测管理、生态保护管理、环境应急管理)、指南规范库、文献库等多种丰富权威的环境资源。知识内容细分到环境各领域,通过分类及检索,可快速获取到相关知识点供参考。